Introducing Backlog Atlas

Backlog Atlas started from a maintainer problem I ran into when I recently started maintaining OmegaConf and Hydra again. Both projects are widely used, but they had been under-maintained for years. Over time, issues accumulated, pull requests piled up, and the backlog became hard to reason about.
With hundreds of issues and pull requests across both repositories, tackling the work directly felt almost impossible. Backlog Atlas came from needing a way to make that backlog visible enough to act on.
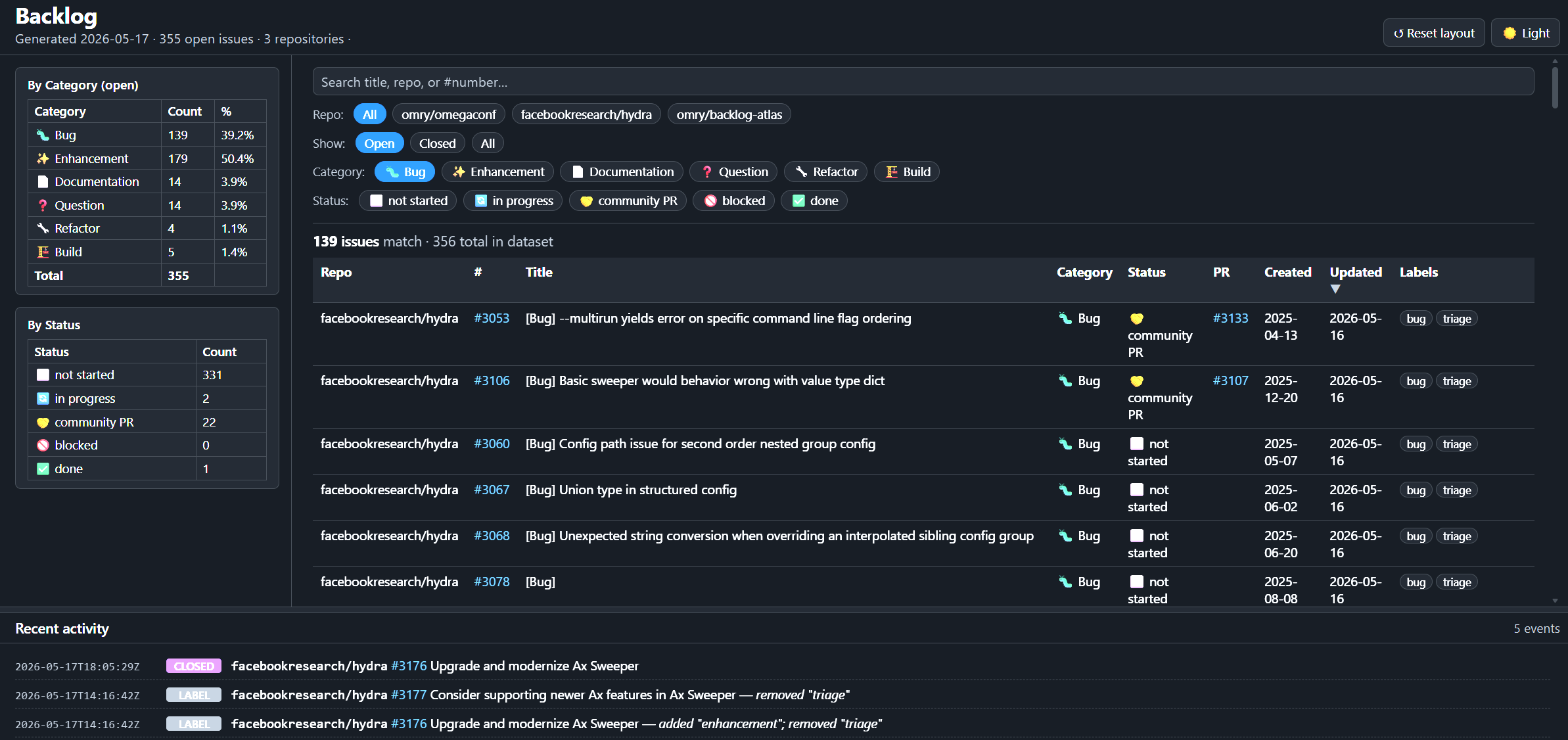
For projects like Hydra and OmegaConf, the backlog is not just a private todo list. It is part of the project surface. Contributors look at it to understand what is happening, users look at it to guess whether something is alive, and I look at it when deciding where attention should go next.
Backlog Atlas collects open issues and pull requests from one or more GitHub repositories and turns them into a searchable dashboard. It shows what is waiting, what changed recently, how issues are distributed across bugs, enhancements, and other categories, and which pull requests need attention.
It publishes that view as static files through GitHub Pages. There is no server to run, no database to maintain, and no hosted product account in the middle.
That shape is deliberate. For open-source maintenance, boring deployment is a feature: generated data should be visible, reviewable, and easy to remove if the tool stops earning its keep.
The first public version already supports a browser-federated atlas view: each
repository publishes its own backlog.json, and one static dashboard can load
multiple downstream repositories and merge them locally in the browser.
The product is in the right shape now, including backlog-atlas atlas install
for batch installing or upgrading all tracked repositories. From here it will
evolve as I use it further and start to receive user feedback.
You can see this repository's dashboard at omry.github.io/backlog-atlas, and the project itself is on GitHub and PyPI.